Cloudflare announced that its R2 object storage and dependent services experienced an outage lasting 1 hour and 7 minutes, causing 100% write and 35% read failures globally.
Cloudflare R2 is a scalable, S3-compatible object storage service with free data retrieval, multi-region replication, and tight Cloudflare integration.
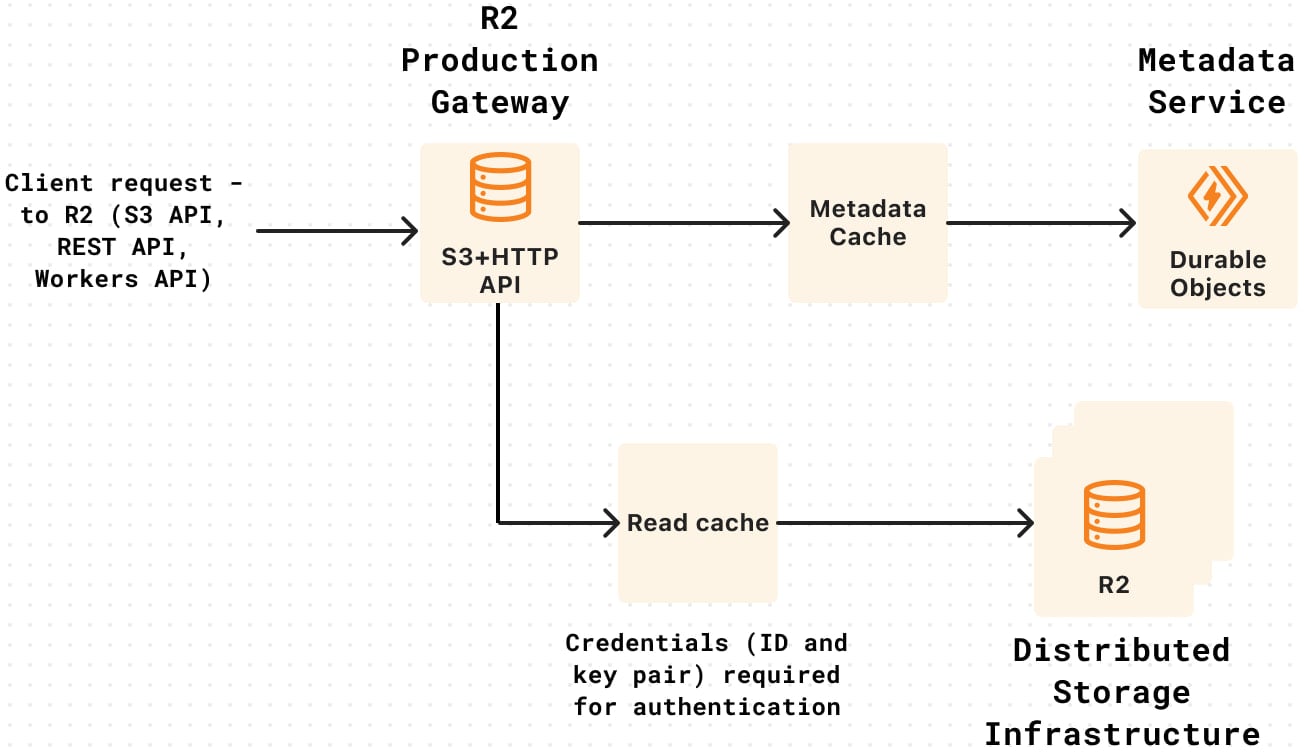
The incident, which lasted between 21:38 UTC and 22:45 UTC, was reportedly caused by a credential rotation that caused the R2 Gateway (API frontend) to lose authentication access to the backend storage.
Specifically, new credentials were mistakenly deployed to a development environment instead of production, and when the old credentials were deleted, the production service was left with no valid credentials.
The issue stemmed from omitting a single command-line flag, ‘–env production,’ which causes the new credentials to be deployed to the production R2 Gateway Worker rather than the production worker.
Source: Cloudflare
Due to the nature of the problem and the way Cloudflare’s services work, the misconfiguration wasn’t made immediately obvious, causing further delays in its remediation.
“The decline in R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure,” explained Cloudflare in its incident report.
“This accounted for a delay in our initial discovery of the problem. Instead of relying on availability metrics after updating the old set of credentials, we should have explicitly validated which token was being used by the R2 Gateway service to authenticate with R2’s storage infrastructure.”
Although the incident did not result in customer data loss or corruption, it still caused partial or full-service degradation for:
- R2: 100% write failures and 35% read failures (cached objects remained accessible)
- Cache Reserve: Higher origin traffic due to failed reads
- Images and Stream: All uploads failed, image delivery dropped to 25% and Stream to 94%
- Email Security, Vectorize, Log Delivery, Billing, Key Transparency Auditor: Various levels of service degradation
To prevent similar incidents from reoccurring in the future, Cloudflare has improved credential logging and verification and now mandates the use of automated deployment tooling to avoid human errors.
The company is also updating standard operating procedures (SOPs) to require dual validation for high-impact actions like credential rotation and plans to enhance health checks for faster root cause detection.
Cloudflare’s R2 service suffered another 1-hour long outage in February, which was also caused by a human error.
An operator responding to an abuse report about a phishing URL in the service turned off the entire R2 Gateway service instead of blocking the specific endpoint.
The absence of safeguards and validation checks for high-impact actions led to the outage, prompting Cloudflare to plan and implement additional measures for improved account provisioning, stricter access control, and two-party approval processes for high-risk actions.

Based on an analysis of 14M malicious actions, discover the top 10 MITRE ATT&CK techniques behind 93% of attacks and how to defend against them.