An attempt to block a phishing URL in Cloudflare’s R2 object storage platform backfired yesterday, triggering a widespread outage that brought down multiple services for nearly an hour.
Cloudflare R2 is an object storage service similar to Amazon S3, designed for scalable, durable, and low-cost data storage. It offers cost-free data retrievals, S3 compatibility, data replication across multiple locations, and Cloudflare service integration.
The outage occurred yesterday when an employee responded to an abuse report about a phishing URL in Cloudflare’s R2 platform. However, instead of blocking the specific endpoint, the employee mistakenly turned off the entire R2 Gateway service.
“During a routine abuse remediation, action was taken on a complaint that inadvertently disabled the R2 Gateway service instead of the specific endpoint/bucket associated with the report,” explained Cloudflare in its post-mortem write-up.
“This was a failure of multiple system level controls (first and foremost) and operator training.”
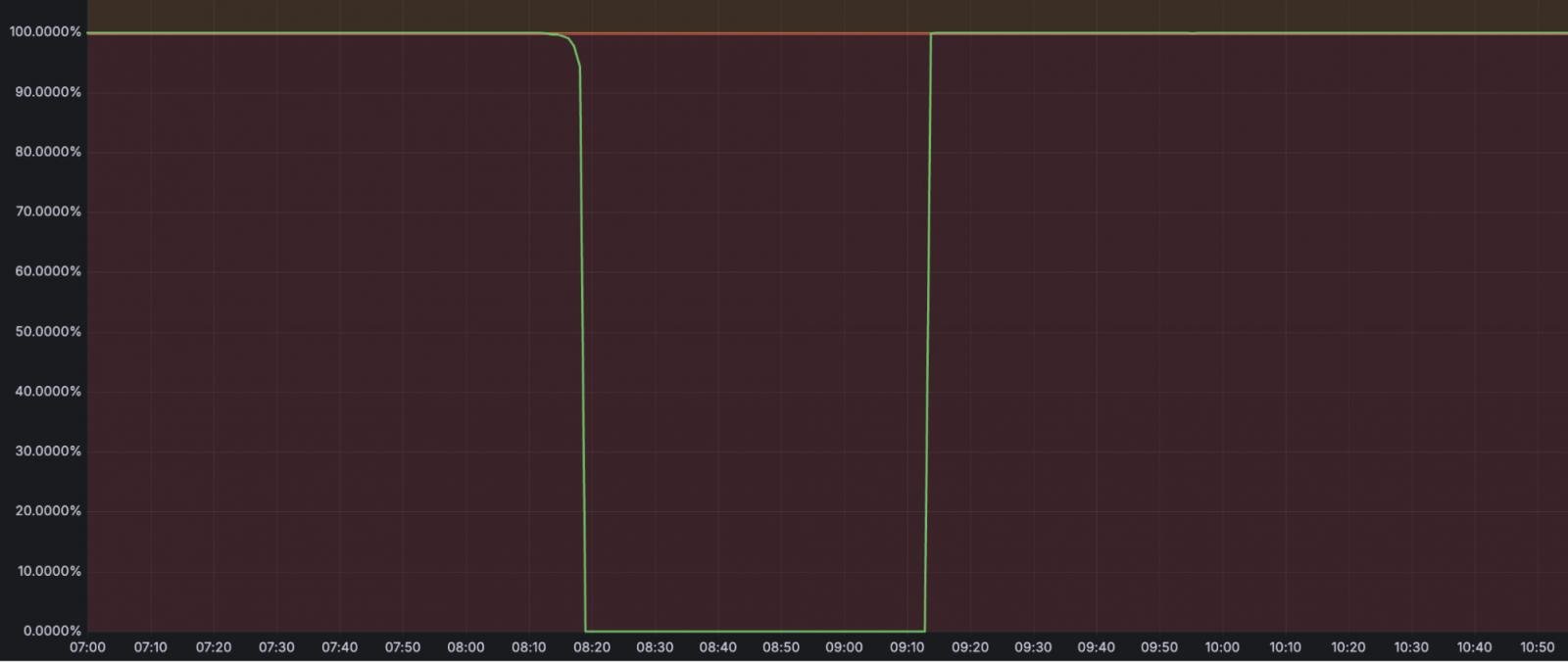
The incident lasted for 59 minutes, between 08:10 and 09:09 UTC, and apart from the R2 Object Storage itself, it also affected services such as:
- Stream – 100% failure in video uploads and streaming delivery.
- Images – 100% failure in image uploads/downloads.
- Cache Reserve – 100% failure in operations, causing increased origin requests.
- Vectorize – 75% failure in queries, 100% failure in insert, upsert, and delete operations.
- Log Delivery – Delays and data loss: Up to 13.6% data loss for R2-related logs, up to 4.5% data loss for non-R2 delivery jobs.
- Key Transparency Auditor – 100% failure in signature publishing & read operations.
There were also indirectly impacted services that experienced partial failures like Durable Objects, which had a 0.09% error rate increase due to reconnections after recovery, Cache Purge, which saw a 1.8% increase in errors (HTTP 5xx) and 10x latency spike, and Workers & Pages, that had a 0.002% deployment failures, affecting only projects with R2 bindings.
Source: Cloudflare
Cloudflare notes that both human error and the absence of safeguards such as validation checks for high-impact actions were key to this incident.
The internet giant has now implemented immediate fixes like removing the ability to turn off systems in the abuse review interface and restrictions in the Admin API to prevent service disablement in internal accounts.
Additional measures to be implemented in the future include improved account provisioning, stricter access control, and a two-party approval process for high-risk actions.
In November 2024, Cloudflare experienced another notable outage for 3.5 hours, resulting in the irreversible loss of 55% of all logs in the service.
That incident was caused by cascading failures in Cloudflare’s automatic mitigation systems triggered by pushing a wrong configuration to a key component in the company’s logging pipeline.